Dataset: fineweb_sample_10B_np_bin
Expt. 1: Baseline
The goal of this experiment was to establish a baseline to compare performance of subsequent experiments. This experiment was run on a L4 GPU on lightning.ai.
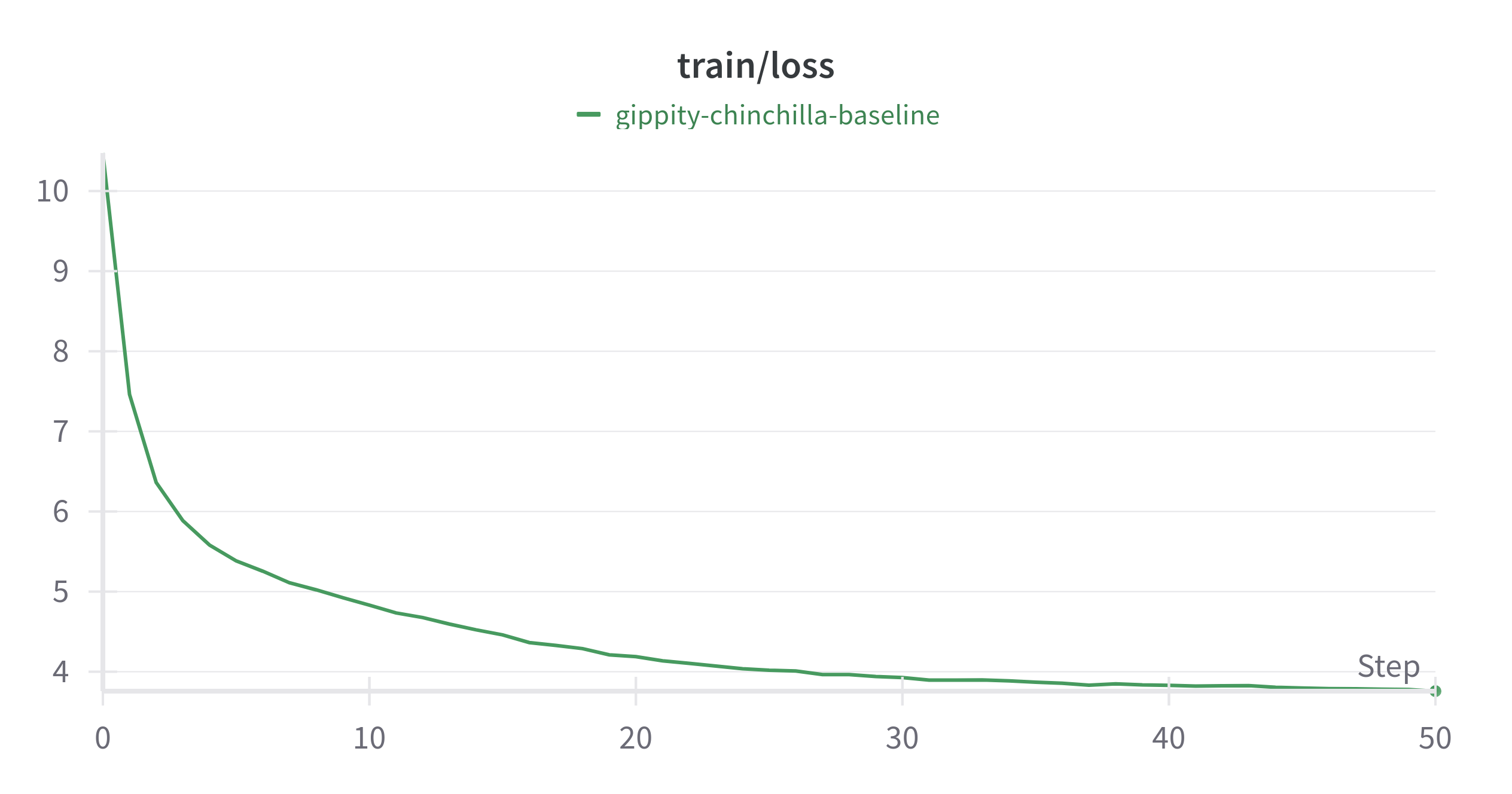
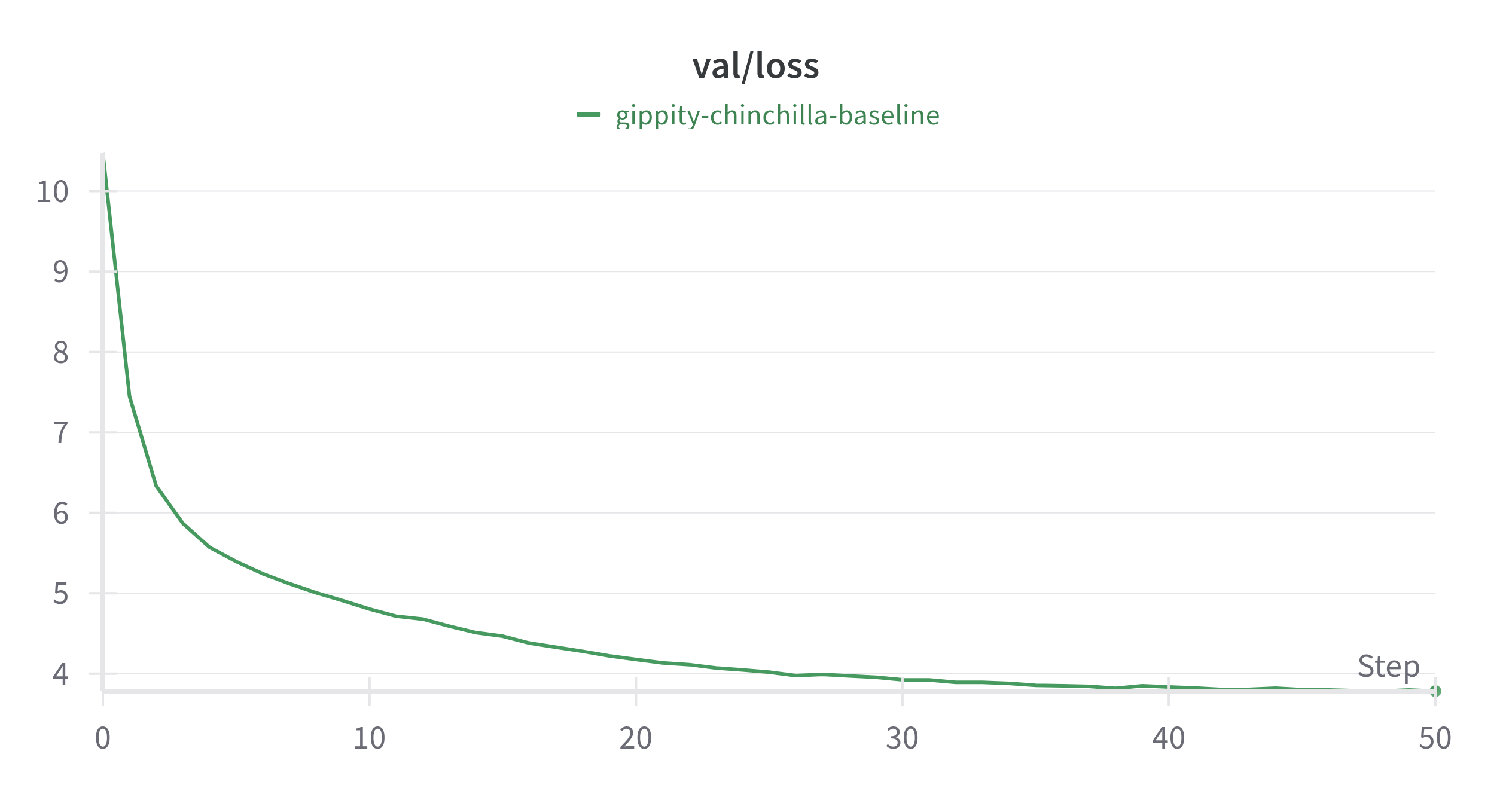
Highlights
- ~35.6M parameter model.
- trained on ~1B tokens from the fineweb dataset.
- nothing fancy. Made little to no modifications to the original nanoGPT code.
NB 1: Code repo
NB 2: Wandb run
Config
- Model Architecture:
n_embd: 512n_head: 8n_layer: 6block_size: 1024bias: falsedropout: 0 (no dropout)
- Optimizer:
learning_rate: 0.0006min_lr: 0.00006beta1: 0.9beta2: 0.95weight_decay: 0.1grad_clip: 1gradient_accumulation_steps: 16
- Learning Rate Schedule:
decay_lr: truewarmup_iters: 100lr_decay_iters: 2000
- Training Duration:
max_iters: 2000batch_size: 32eval_interval: 40eval_iters: 50
- Misc:
device: “cuda”dtype: “bfloat16”backend: “nccl”compile: true
- Logging:
wandb_log: truewandb_project: “gippity”wandb_run_name: “gippity-chinchilla-baseline”
Expt. 2:
We use Rotary Positional embeddings in place of learned positional embeddings and RMSNorm in place of LayerNorm.
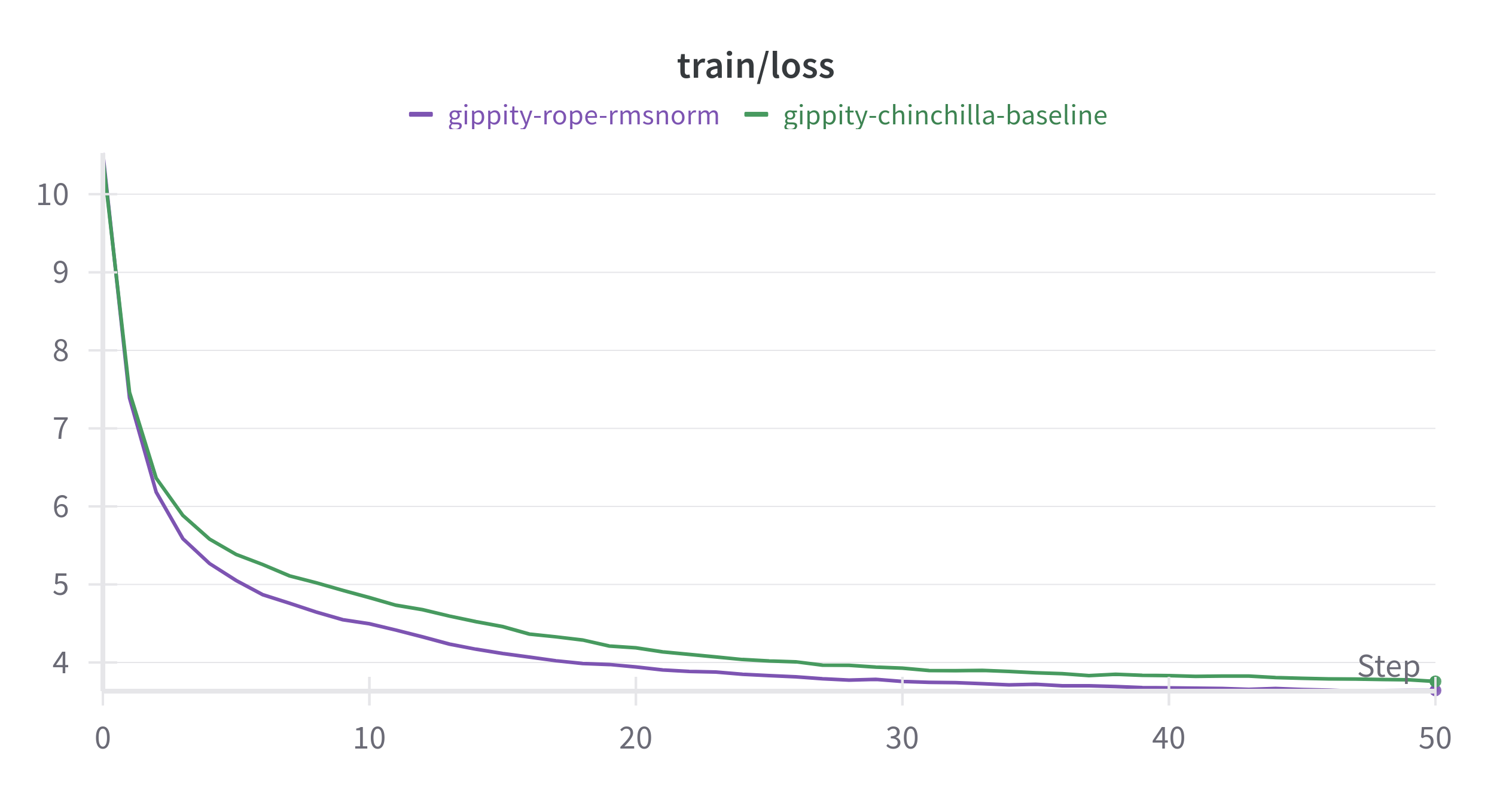
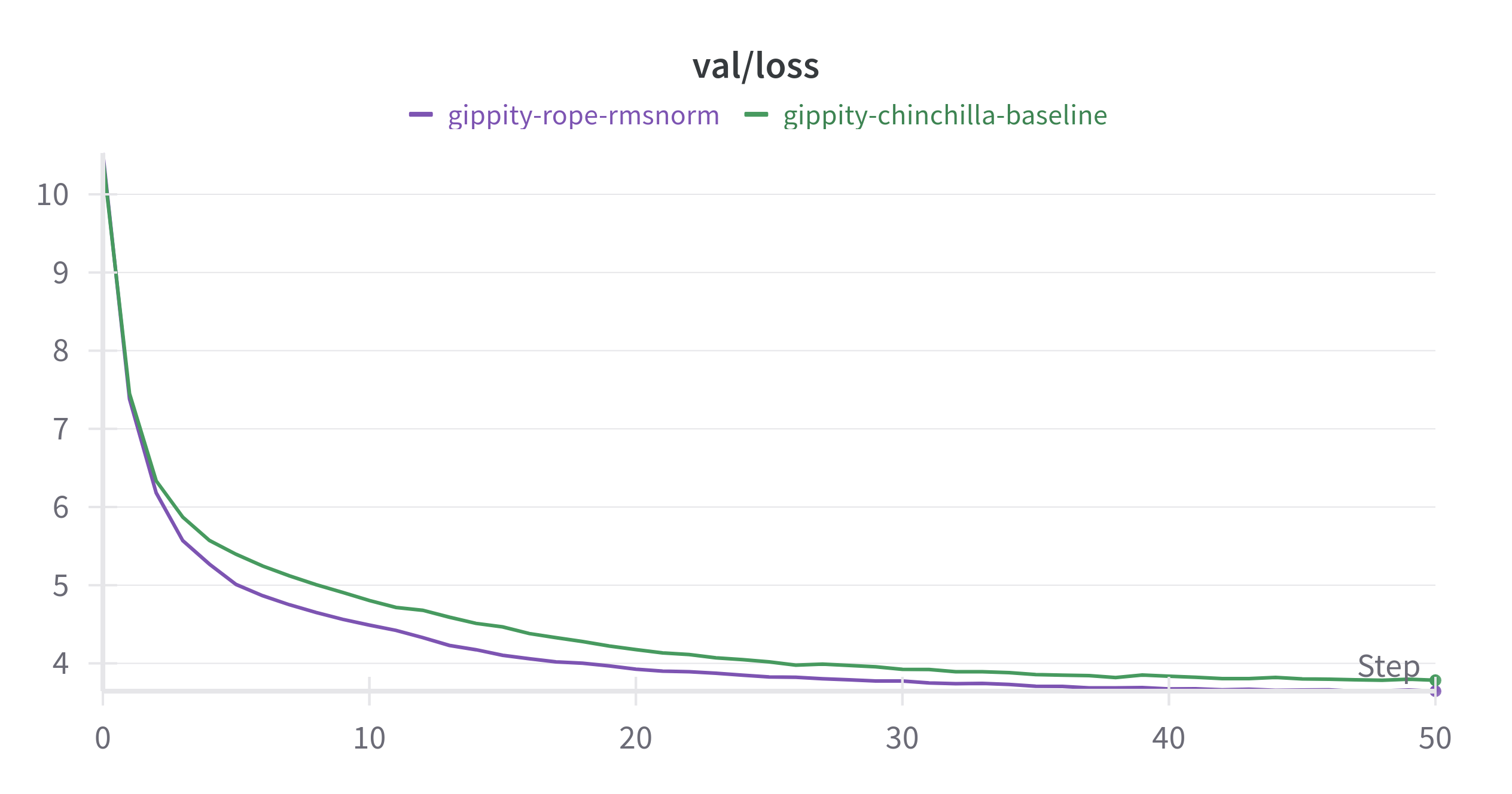
Highlights
- shows better loss than baseline (converges faster).
- reduced VRAM usage due to removal of learned positional embeddings.
- hence the batch size can be increased and gradient accumulation steps decreased.
- faster training due to lesser parameters and lower gradient accumulation steps.
References
- You could have designed state of the art positional encoding
- Rotary Embeddings: A Relative Revolution
- RoFormer: Enhanced Transformer with Rotary Position Embedding
NB 1: Code repo
NB 2: Wandb run
Config
- Model Architecture:
n_embd: 512n_head: 8n_layer: 6block_size: 1024bias: falsedropout: 0 (no dropout)
- Optimizer:
learning_rate: 0.0006min_lr: 0.00006beta1: 0.9beta2: 0.95weight_decay: 0.1grad_clip: 1gradient_accumulation_steps: 8
- Learning Rate Schedule:
decay_lr: truewarmup_iters: 100lr_decay_iters: 2000
- Training Duration:
max_iters: 2000batch_size: 64eval_interval: 40eval_iters: 50
- Misc:
device: “cuda”dtype: “bfloat16”backend: “nccl”compile: true
- Logging:
wandb_log: truewandb_project: “gippity”wandb_run_name: “gippity-rope-rmsnorm”